使用LSTM网络进行文本分类
摘要: 本示例教程将会演示如何使用TensorLayerX的LSTM神经网络来完成文本分类任务。这是一个较为简单的示例,将会使用一个由嵌入层和LSTM构成的网络完成Imdb数据集的图像分类任务。
本教程的完整代码:imdb_lstm_simple.py
深度学习处理文本、语音等数据时一般会将其转换为序列数据,然后使用循环神经网络来处理。以文本数据为例,最简单的方法就是将文本转换为词向量,然后将词向量作为序列数据。
我们首先需要一个包含所有词的词典vocabulary,每个词都有一个唯一的编号ID,然后我们将文本转换为ID序列,再将ID序列转换为词向量序列。以一个句子举例:" I love TensorLayerX",这句话一共有3个词,我们可以将其转换为ID序列[1, 2, 3],然后将ID序列转换为one-hot词向量序列[[1, 0, 0], [0, 1, 0], [0, 0, 1]],其中每个词向量的维度为3,即词典中有3个词。
如果每个样本代表一句话或者一段文本,那么一个batch中的B个数据就可以看成是B个句子或者段落,每个句子或者段落的长度为T,每个句子或者段落中的每个词的词向量的维度为D,那么一个batch的数据就可以看成是一个[B, T, D]的三维数据。
在TensorLayerX中,我们提供了tlx.text.nlp模块来处理文本数据,包括将文本转换为词向量,以及将词向量转换为文本等功能。
LSTM算法简介
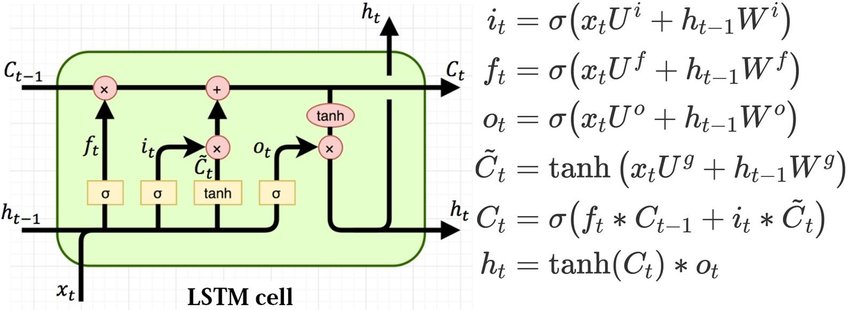
一般来说,卷积神经网络被用来处理图像数据的任务,而文本等序列数据的任务一般使用循环神经网络 RNN(Recurrent Neural Network) 来处理。
其中,LSTM(长短期记忆) 网络是循环神经网络的一种,是为了解决一般的RNN存在的长期依赖问题而专门设计出来的。在标准RNN中,这个重复的结构模块只有一个非常简单的结构,例如一个全连接层使用 tanh 作为激活函数。
RNN模型在同一个单元(Cell)中,每个时刻利用当前t和之前t-1输入,产生当前时刻的输出,能够解决一定时序的问题,但是受到短时记忆影响,很难将信息从较早的时间传到较晚的时间。LSTM进一步模拟了人类记忆思考的过程,通过引入门结构(forget,input,output三种门结构),可以学习如何记住和忘记信息,能够将序列的信息一直传递下去,能够将较早的信息也引入到较晚的时间中来,从而克服短时记忆。
一、环境配置
本教程基于TensorLayerX 0.5.6 编写,如果你的环境不是本版本,请先参考官网安装。
TensorlayerX目前支持包括TensorFlow、Pytorch、PaddlePaddle、MindSpore作为计算后端,指定计算后端的方法也非常简单,只需要设置环境变量即可
import os
os.environ['TL_BACKEND'] = 'paddle'
# os.environ['TL_BACKEND'] = 'tensorflow'
# os.environ['TL_BACKEND'] = 'mindspore'
# os.environ['TL_BACKEND'] = 'torch'
引入需要的模块
import tensorlayerx as tlx
from tensorlayerx.nn import Module
from tensorlayerx.nn import Linear, LSTM, Embedding
from tensorlayerx.dataflow import Dataset
import numpy as np
二、加载数据集
本案例我们使用IMDB数据集进行训练,这是一个从电影评论网站IMDB收集的评论文本情感分类数据集,算法分析文本内容判断属于2种情绪之一。
本案例将会使用TensorLayerX提供的API完成数据集的下载并为后续的训练任务准备好数据迭代器。
prev_h = np.random.random([1, 200, 64]).astype(np.float32)
prev_h = tlx.convert_to_tensor(prev_h)
X_train, y_train, X_test, y_test = tlx.files.load_imdb_dataset('data', nb_words=20000, test_split=0.2)
seq_Len = 200
vocab_size = len(X_train) + 1
class ImdbDataset(Dataset):
def __init__(self, X, y):
self.X = X
self.y = y
def __getitem__(self, index):
data = self.X[index]
data = np.concatenate([data[:seq_Len], [0] * (seq_Len - len(data))]).astype('int64') # set
label = self.y[index].astype('int64')
return data, label
def __len__(self):
return len(self.y)
train_dataset = ImdbDataset(X=X_train, y=y_train)
三、组建网络
接下来使用TensorLayerX定义一个使用了一个嵌入层( Embedding ),和一个LSTM层的神经网络。 嵌入层将输入的词序列转变为嵌入向量序列,经过LSTM计算隐藏状态后,再通过两个线性变换层组成的分类网络,来把一个字词序列通过循环神经网络映射为2个输出,这对应着2种情绪的类别。
class ImdbNet(Module):
def __init__(self):
super(ImdbNet, self).__init__()
self.embedding = Embedding(num_embeddings=vocab_size, embedding_dim=64)
self.lstm = LSTM(input_size=64, hidden_size=64)
self.linear1 = Linear(in_features=64, out_features=64, act=tlx.nn.ReLU)
self.linear2 = Linear(in_features=64, out_features=2)
def forward(self, x):
x = self.embedding(x)
x, _ = self.lstm(x, [prev_h, prev_h])
x = tlx.reduce_mean(x, axis=1)
x = self.linear1(x)
x = self.linear2(x)
return x
打印模型结构
ImdbNet(
(embedding): Embedding(num_embeddings=20001, embedding_dim=64)
(lstm): LSTM(input_size=64, hidden_size=64, num_layers=1, dropout=0.0, bias=True, bidirectional=False, name='lstm_1')
(linear1): Linear(out_features=64, ReLU, in_features='64', name='linear_1')
(linear2): Linear(out_features=2, No Activation, in_features='64', name='linear_2')
)
四、模型训练&预测
接下来,用Model高级接口来快速开始模型的训练,将会:
使用 tlx.optimizers.Adam 优化器来进行优化。
使用 tlx.losses.softmax_cross_entropy_with_logits 来计算损失值。
使用 tensorlayerx.dataflow.DataLoader 来加载数据并组建batch。
使用 tlx.model.Model 高级模型接口构建用于训练的模型
n_epoch = 5
batch_size = 64
print_freq = 2
train_loader = tlx.dataflow.DataLoader(train_dataset, batch_size=batch_size, shuffle=True)
optimizer = tlx.optimizers.Adam(1e-3)
metric = tlx.metrics.Accuracy()
loss_fn = tlx.losses.softmax_cross_entropy_with_logits
model = tlx.model.Model(network=net, loss_fn=loss_fn, optimizer=optimizer, metrics=metric)
model.train(n_epoch=n_epoch, train_dataset=train_loader, print_freq=print_freq, print_train_batch=True)
Epoch 1 of 5 took 1.2969748973846436
train loss: [0.6930715]
train acc: 0.546875
Epoch 1 of 5 took 1.305964708328247
train loss: [0.69317925]
train acc: 0.5078125
......
Epoch 5 of 5 took 2.8309640884399414
train loss: [0.18543097]
train acc: 0.9305111821086262
The End
从上面的示例可以看到,在Imdb数据集上,使用简单的LSTM神经网络,用TensorLayerX可以达到93%以上的准确率。你也可以通过调整网络结构和参数,达到更好的效果。


