计算机视觉是人工智能的一个分支,它旨在让计算机能够理解图像。计算机视觉的目标是模拟人类的视觉能力,即通过使用计算机算法来识别和理解图像中的物体和场景。它可以应用于自动驾驶汽车、安全监控、图像搜索和图像识别等领域。通过计算机视觉技术,计算机可以从图像中提取有用的信息,并做出相应的决策。
TensorLayerX提供大量先进的、经过充分验证的智能视觉模型,覆盖各类任务场景。多种开箱即用的算法,可以部署在各种平台上,为开发者提供高效顺畅的开发体验。
计算机视觉常见任务介绍
计算机视觉的核心任务就是从图像中解析出可供计算机理解的信息,根据任务的不同主要有
二是检测(Detection)。分类任务关心整体,给出的是整张图片的内容描述,而检测则关注特定的物体目标,要求同时获得这一目标的类别信息和位置信息。相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因而,检测模型的输出是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置(常用矩形检测框的坐标表示)。
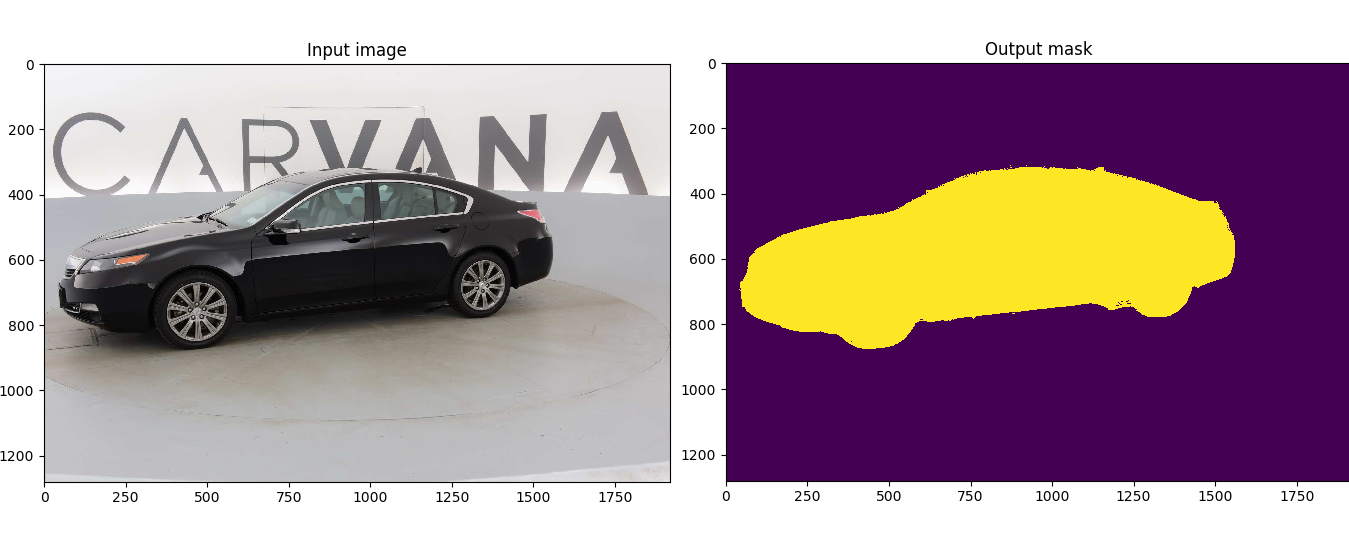
三是分割(Segmentation)。分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,而后者是检测任务的拓展,要求描述出目标的轮廓(相比检测框更为精细)。分割是对图像的像素级描述,它赋予每个像素类别(实例)意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。
图像分类(Image Classification)是将图像结构化若干种类别的信息,用事先确定好的类别来描述图片。这一任务是最简单、最基础的图像理解任务,也是深度学习模型最先取得突破和实现大规模应用的任务。

ImageNet是图像分类任务的数据集,在此数据集上训练的执行图像分类任务的神经网络,因为具有较好的特征提取能力,经常被用做其他任务基干网络(backbone)。TensorLayerX提供了多种在ImageNet上训练好的神经网络模型,包括:
图像分类是从图像的整体来进行理解,而目标检测(Object Detection)则要求同时获得图像中目标的类别信息和位置信息。算法需要从背景中分离出感兴趣的目标,并确定目标的描述类别和位置。因此,目标检测的输出的信息是一个列表,列表的每一项使用一个数据组给出检出目标的类别和位置,一般用矩形检测框(Bounding Box)的坐标表示。

TensorLayerX提供了多种先进的目标检测算法,他们在MSCOO数据集上训练,适用于大多数的目标检测任务:
来自Meta的《End-to-end object detection with Transformers》,是Transformer在目标检测领域的成功应用。利用Transformer中attention机制能够有效建模图像中的长程关系(long range dependency),简化目标检测的pipeline,构建端到端的目标检测器。

来自百度的改进版YOLO算法,实现精确高效的目标检测。
图像分割包括语义分割(semantic segmentation)和实例分割(instance segmentation),前者是对前背景分离的拓展,要求分离开具有不同语义的图像部分,将每个像素归纳为一个预定的类别。而后者是检测任务的拓展,要求描述出每个目标的轮廓,精确到每个像素。分割是对图像的像素级描述,它赋予每个像素类别意义,适用于理解要求较高的场景,如无人驾驶中对道路和非道路的分割。

TensorLayerX提供了多种图像分割算法:
来自《U-Net: Convolutional Networks for Biomedical Image Segmentation》,用于图像分割任务的全卷积神经网络,可以用于自动驾驶感知、医疗影像分析、遥感图像分析等。
人脸识别是近年来计算机视觉大规模商业化最成功的领域之一,我们现在的手机人脸认证、安防监控等都使用了人脸识别技术。一般来说,完整的人脸识别过程首先要定位图像中的人脸,这是一个目标检测的过程,然后再识别每一个人脸目标的五官边缘的特征点信息,最后提取人脸的特征向量用于识别身份信息。

TensorLayerX提供了用于人脸检测的RetinaFace算法、用于人脸特征点检测的PFLD算法、用于人脸嵌入特征提取的ArcFace算法
人体姿态估计
人体姿态估计的目标是从给定的图像或视频中确定人的身体关键点的位置或空间位置,这些关键点一般是关节等人体刚性部分。人体姿态估计的算法可以应用于运动视频分析、行为分析、健康监护等。

TensorLayerX提供了先进的人体姿态估计算法:
在计算的过程中保持高分辨率信息表达,可以用来完成人体关键点检测、图像分割等任务。
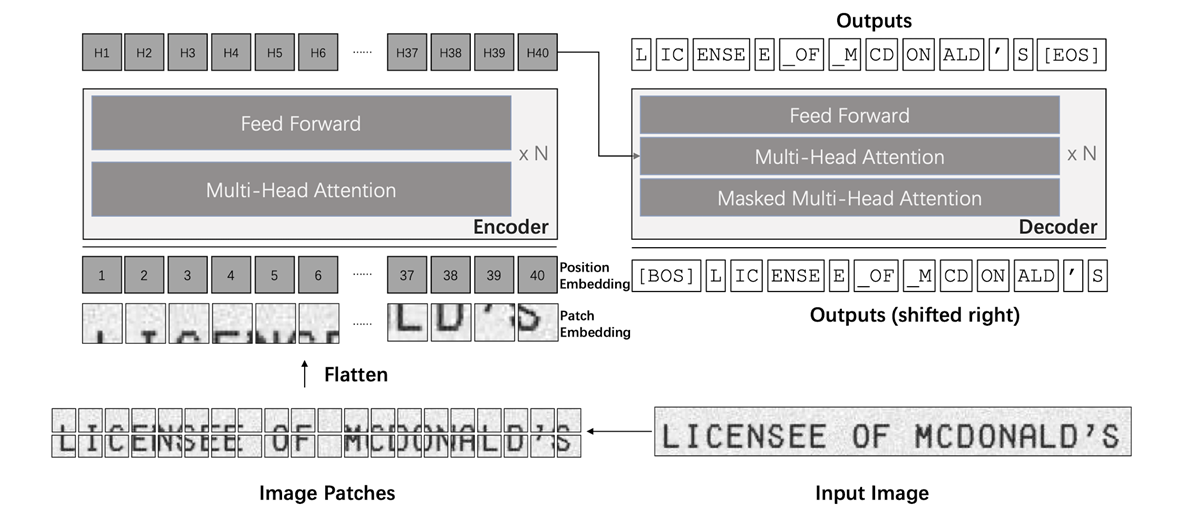
光学字符识别(OCR)的任务是从图片中识别文字字符,被广泛应用于表单识别、自动信息录入等场景。一般来说,完整的OCR识别过程包括字符定位、字符识别等过程。

TensorLayerX提供了先进的文本识别 OCR 模型:
首个利用预训练模型的端到端基于 Transformer 的文本识别 OCR 模型