Computer vision is a branch of artificial intelligence, which aims to enable computers to understand images. The goal of computer vision is to simulate human visual ability, that is, to recognize and understand objects and scenes in images by using computer algorithms. It can be applied to autonomous vehicle, image search, image recognition and other fields. Through computer vision technology, computers can extract useful information from images and make corresponding decisions.
TensorLayerX provides a large number of advanced and fully validated intelligent visual models, covering various task scenarios. A variety of out-of-the-box algorithms can be deployed on various platforms to provide developers with efficient and smooth development experience.
The "End-to-end object detection with Transformers" from Meta is a successful application of Transformer in the field of object detection. Using the attention method in Transformer can effectively model the long range dependence in the image, simplify the pipeline of target detection, and build an end-to-end object detector.

The improved YOLO algorithm from Baidu achieves accurate and efficient object detection.
Neural networks trained on ImageNet to perform image classification tasks, often used as a backbone network
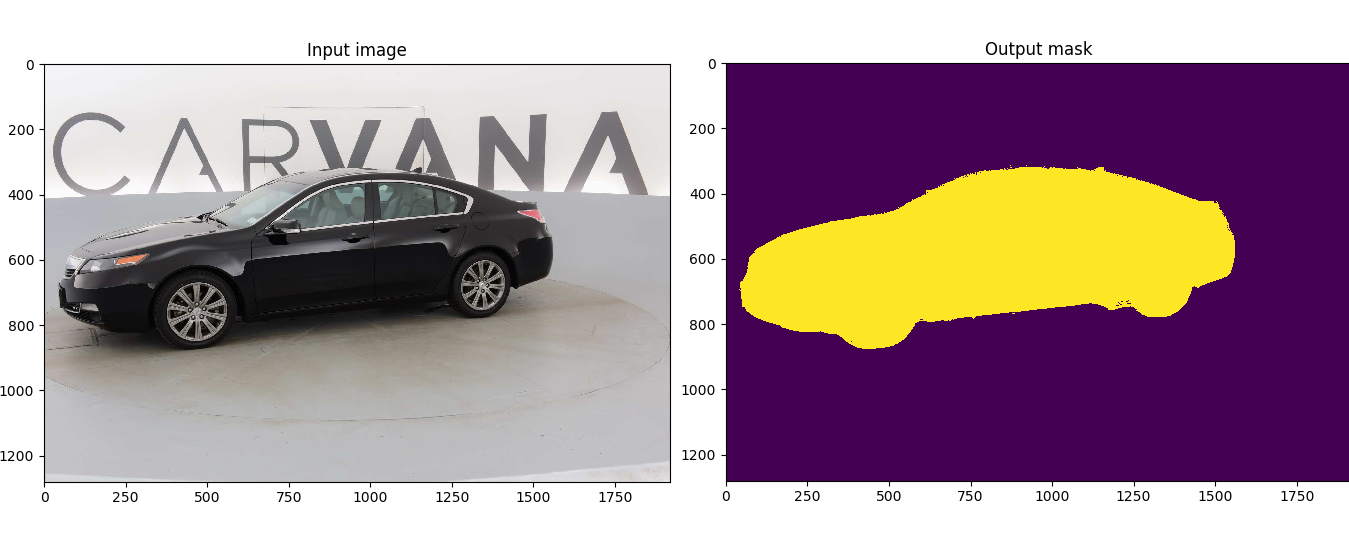
From “U-Net: Convolutional Networks for Biomedical Image Segmentation”, a full-convolution neural network for image segmentation tasks, which can be used for auto-driving perception, medical image analysis, remote sensing image analysis, and so on.
RetinaFace algorithm for face detection, PFLD algorithm for face feature point detection, and ArcFace algorithm for face embedded feature extraction
The algorithm maintains high-resolution information expression during the calculation process, and can be used for human key point detection, image segmentation and other tasks.

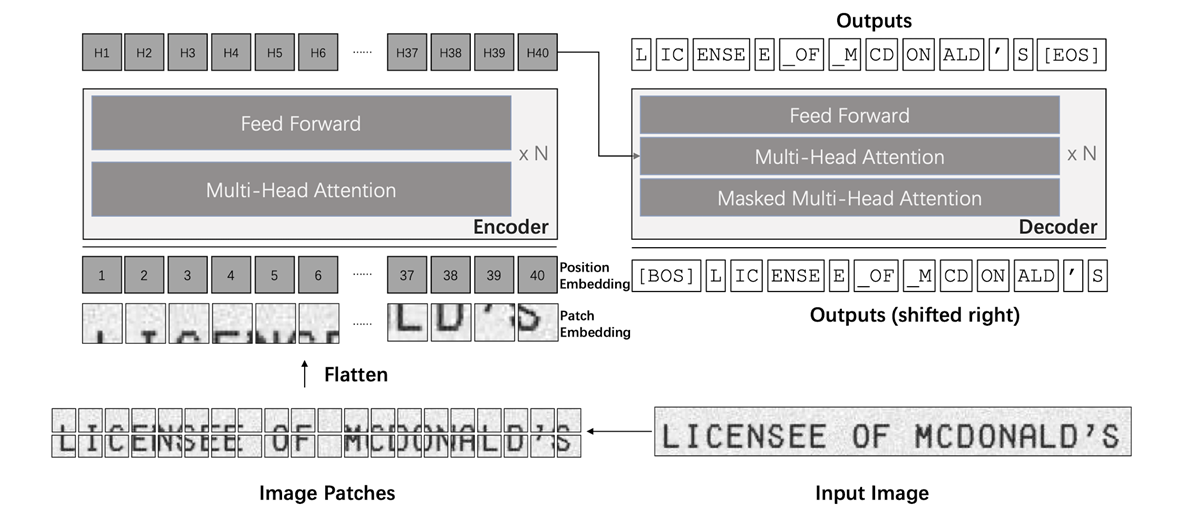
First end-to-end Transformer-based text recognition OCR model using a pre-training model